简介
PaddleOCR是百度开源的超轻量级文字识别模型套件,提供了数十种文本检测、识别模型,旨在打造一套丰富、领先、实用的文字检测、识别模型/工具库,助力使用者训练出更好的模型,并应用落地。目前,不仅开源了超轻量8.6M中英文模型,而且用户可以自定义训练,使用自己的数据集Fine-tune一下就能达到非常好的效果。并且提供了多种硬件推理(服务器端、移动端、嵌入式端等全支持)的一整套部署工具,是OCR文字识别领域工业级应用的绝佳选择。
百度飞桨(PaddlePaddle)官网:https://www.paddlepaddle.org.cn/install/quick
安装
百度飞桨提供了多种安装方式,这里使用的是docker方式安装,比较简单便捷。
安装CPU版
百度飞桨提供了GPU版和CPU版,我这里安装的CPU版。
1.拉取预安装 PaddlePaddle 的镜像
docker pull registry.baidubce.com/paddlepaddle/paddle:2.4.2
2.用镜像构建并进入Docker容器:
docker run --name paddle -it -v $PWD:/paddle registry.baidubce.com/paddlepaddle/paddle:2.4.2 /bin/bash
运行该命令后,将启动并进入docker容器内部,同时将服务器的当前目录映射到了容器里的/paddle目录。
参数说明:--name paddle:设定 Docker 的名称,paddle 是自己设置的名称;-it:参数说明容器已和本机交互式运行;-v $PWD:/paddle:指定将当前路径(PWD 变量会展开为当前路径的绝对路径)挂载到容器内部的 /paddle 目录;registry.baidubce.com/paddlepaddle/paddle:2.4.2:指定需要使用的 image 名称,您可以通过docker images命令查看;/bin/bash 是在 Docker 中要执行的命令
补充说明
当您需要第二次进入 Docker 容器中,使用如下命令:
启动之前创建的容器:
docker start <Name of container>
进入启动的容器:
docker attach <Name of container>
如何卸载
通过docker rm <Name of container>来直接删除 Docker 容器
安装库
进入docker容器后,在容器中执行以下命令:
# 安装 PaddlePaddle
python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装 PaddleHub 可以添加 --verbose,查看进度
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
# 该Module依赖于第三方库shapely、pyclipper,使用该Module之前,请先安装shapely、pyclipper
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
定义待预测数据
在容器中,创建一个picture.txt文件,将预测图片的路径存放在里面,内容如下:
./images/231242.jpg
./images/234730.jpg
测试输出:
创建一个1.py,内容如下:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 将预测图片存放在一个文件中(picture.txt)
with open('picture.txt', 'r') as f:
test_img_path=[]
for line in f:
test_img_path.append(line.strip())
# 显示图片
img1 = mpimg.imread(line.strip())
plt.figure(figsize=(10, 10))
plt.imshow(img1)
plt.axis('off')
plt.show()
print(test_img_path) # => ['images/231242.jpg', 'images/234730.jpg']
然后执行:
python 1.py
加载预训练模型
PaddleHub提供了以下文字识别模型:
移动端的超轻量模型:体积小,chinese_ocr_db_crnn_mobile
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
识别文字算法均采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module支持直接预测。 移动端与服务器端主要在于骨干网络的差异性,移动端采用MobileNetV3,服务器端采用ResNet50_vd
我这里使用的是移动端预训练模型。
创建一个2.py,内容如下:
import paddlehub as hub
# 加载移动端预训练模型
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服务端可以加载大模型,效果更好
# ocr = hub.Module(name="chinese_ocr_db_crnn_server")
执行python 2.py,如果提示以下错误:
ImportError: cannot import name 'deprecated' from 'typing_extensions' (/usr/local/lib/python3.7/dist-packages/typing_extensions.py)
则说明typing_extensions的版本太低,需要卸载后重新安装:
pip uninstall typing_extensions
pip install typing_extensions

预测
创建一个3.py,内容如下:
import paddlehub as hub
import cv2
# 加载移动端预训练模型
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服务端可以加载大模型,效果更好
# ocr = hub.Module(name="chinese_ocr_db_crnn_server")
# 将预测图片存放在一个文件中(picture.txt)
test_img_path = []
with open('picture.txt', 'r') as f:
for line in f:
test_img_path.append(line.strip())
print("预测图片 => ", test_img_path)
# 读取测试文件夹test.txt中的照片路径
np_images = [cv2.imread(image_path) for image_path in test_img_path]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=True, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.5) # 识别中文文本置信度的阈值;
for result in results:
data = result['data']
save_path = result['save_path']
for infomation in data:
print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ', infomation['text_box_position'])
执行python 3.py,输出: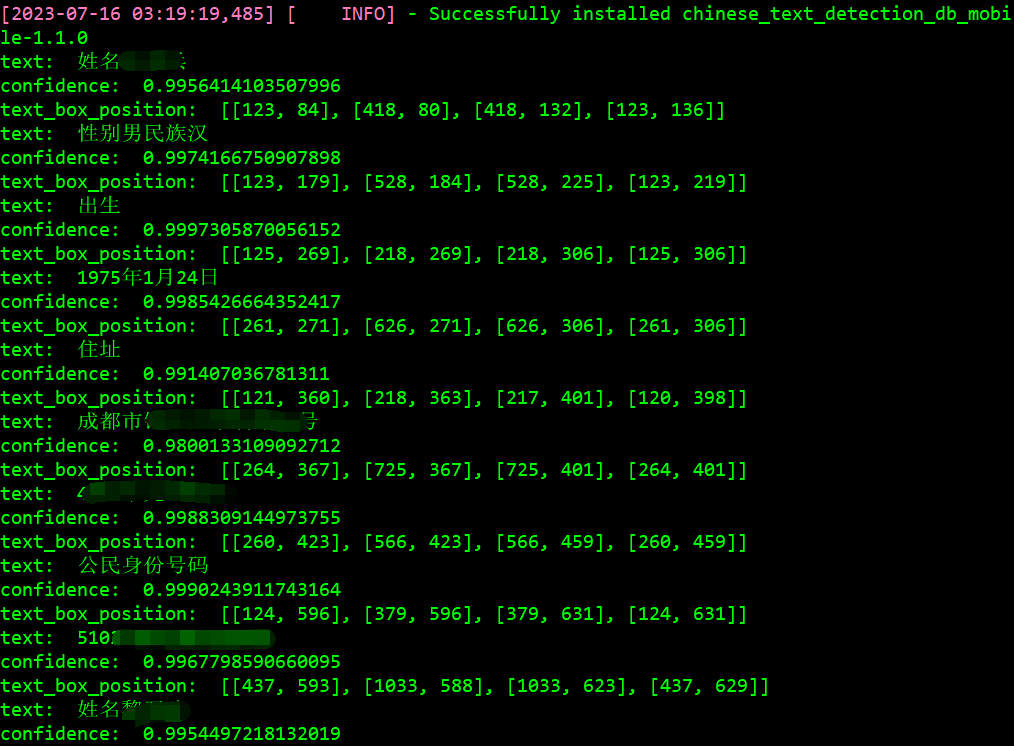
同时会将输出结果的图片保存至ocr_result目录:
参考:
https://www.cnblogs.com/vipsoft/archive/2023/05/15/17384874.html
