简介
Elasticsearch是一个高度可扩展的全文搜索和分析引擎,基于Apache Lucence(事实上,Lucence也是百度所采用的搜索引擎)构建,能够对大容量的数据进行接近实时的存储、搜索和分析操作。
安装
安装Java8
在安装Elasticsearch前,首先需要安装JAVA环境。
可以先执行以下命令查看是否安装:
java -version
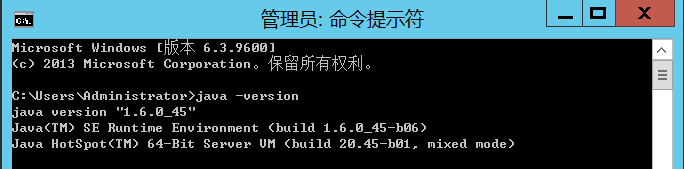
如果没有安装需要先到oracle官网下载jdk-6u45-windows-x64.exe并安装。下载时会提示需要登录账号才能下载。
配置Java环境变量
在系统环境变量中,新建JAVA_HOME变量,值为:C:\Program Files\Java\jdk1.6.0_45: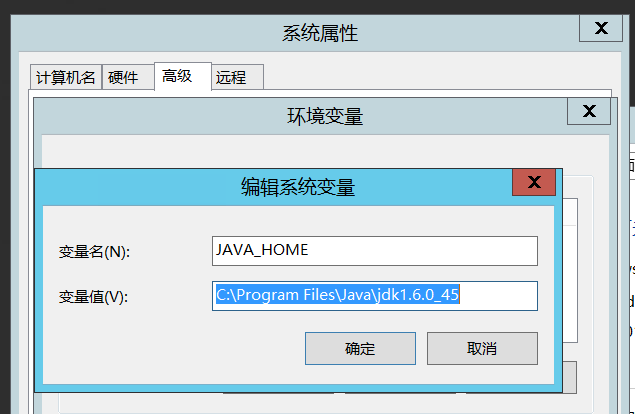
在path这个系统环境变量中,添加:;%JAVA_HOME%\bin: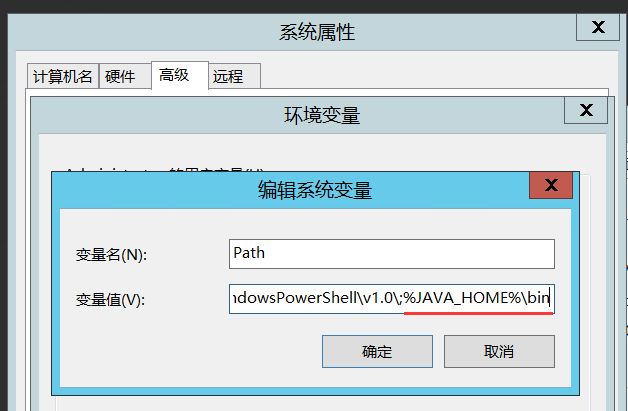
添加CLASSPATH变量,值为:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;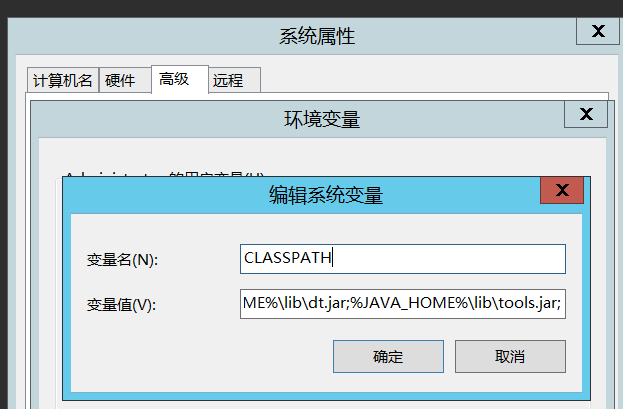
打开cmd命令行,输入javac -version,如果成功执行命令,则说明jdk安装成功。
安装Elasticsearch
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
目前最新版是8.4.1
下载后解压压缩包,在config/elasticsearch.yml末尾添加:
ingest.geoip.downloader.enabled: false
然后修改如下配置:
network.host: 127.0.0.1
http.port: 9200
双击bin/elasticsearch.bat运行后,报错,再次打开elasticsearch.yml,修改:
xpack.security.enabled: false
双击elasticsearch.bat运行,浏览器访问127.0.0.1:9200,看到以下界面则说明安装成功: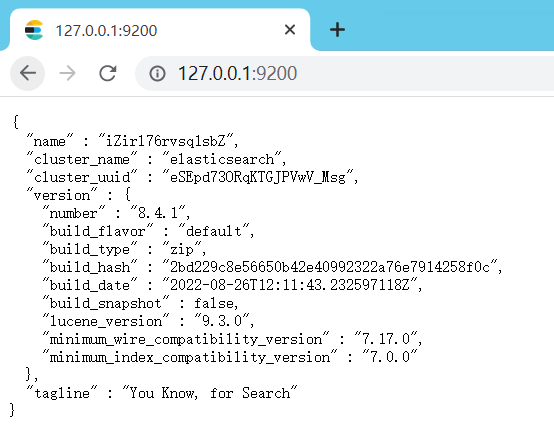
基本使用
创建索引
PUT http://127.0.0.1:9200/<index>
<index>:索引的名称
注:也可以不创建索引,后续在添加文档时,如果没有索引会自动创建。
删除索引
DELETE http://127.0.0.1:9200/<index>
添加/更新文档
POST http://127.0.0.1:9200/<index>/_doc/<_id>
<index>:索引的名称<_id>:文档的唯一标识符
例如:
POST http://127.0.0.1:9200/movies/_doc/1
{"id":1,"title":"Kung Fu Panda","overview":"When the Valley of Peace is threatened, lazy Po the panda discovers his destiny as the \"chosen one\" and trains to become a kung fu hero, but transforming the unsleek slacker into a brave warrior won't be easy. It's up to Master Shifu and the Furious Five -- Tigress, Crane, Mantis, Viper and Monkey -- to give it a try.","genres":["Action","Adventure","Animation","Family","Comedy"],"poster":"https://image.tmdb.org/t/p/w500/wWt4JYXTg5Wr3xBW2phBrMKgp3x.jpg","release_date":1212537600}
可以使用Postman来操作: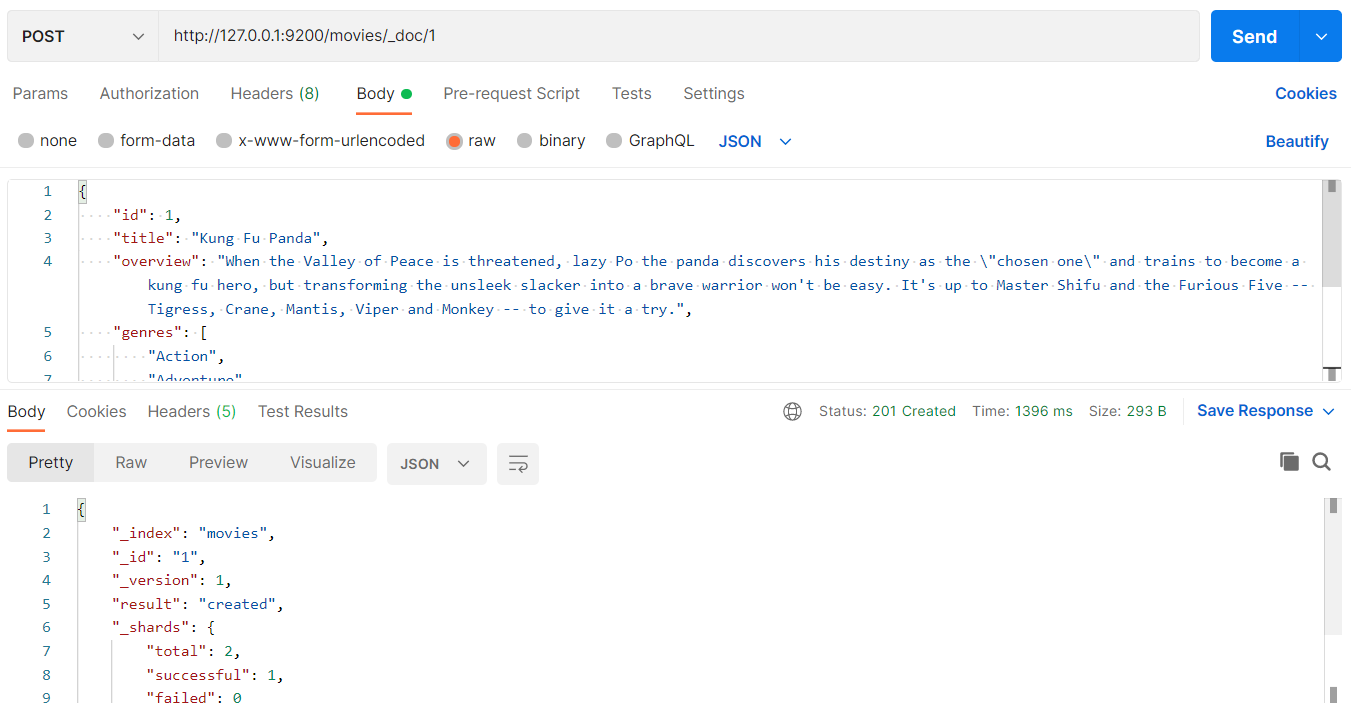
批量添加文档
PUT http://127.0.0.1:9200/<index>/_bulk
例如:
PUT http://127.0.0.1:9200/movies/_bulk
{"index":{"_id":1}}
{"id":1,"title":"Kung Fu Panda","overview":"When the Valley of Peace is threatened, lazy Po the panda discovers his destiny as the \"chosen one\" and trains to become a kung fu hero, but transforming the unsleek slacker into a brave warrior won't be easy. It's up to Master Shifu and the Furious Five -- Tigress, Crane, Mantis, Viper and Monkey -- to give it a try.","genres":["Action","Adventure","Animation","Family","Comedy"],"poster":"https://image.tmdb.org/t/p/w500/wWt4JYXTg5Wr3xBW2phBrMKgp3x.jpg","release_date":1212537600}
{"index":{"_id":2}}
{"id":2,"title":"Batman","overview":"Batman has not been seen for ten years. A new breed of criminal ravages Gotham City, forcing 55-year-old Bruce Wayne back into the cape and cowl. But, does he still have what it takes to fight crime in a new era?","genres":["Action","Animation","Mystery"],"poster":"https://image.tmdb.org/t/p/w500/kkjTbwV1Xnj8wBL52PjOcXzTbnb.jpg","release_date":1345507200}
注:提交数据的最后一行有一行空行\n不能省略。
获取文档
GET http://127.0.0.1:9200/<index>/_doc/<_id>
例如:
GET http://127.0.0.1:9200/movies/_doc/1
删除文档
DELETE http://127.0.0.1:9200/<index>/_doc/<_id>
搜索文档
URL参数查询
GET http://127.0.0.1:9200/<index>/_search?q=<keyword>&sort=<field>:<direction>
q:使用q参数来运行查询参数搜索<keyword>:查询字符串sort:排序
例如:
GET http://127.0.0.1:9200/movies/_search?q=panda&sort=id:asc
url中的更多参数请查看官方文档
响应正文
搜素后得到如下响应正文:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "movies",
"_id": "1",
"_score": null,
"_ignored": [
"overview.keyword"
],
"_source": {
"id": 1,
"title": "Kung Fu Panda",
"overview": "When the Valley of Peace...",
"genres": [
"Action",
...
],
"poster": "https://image.xxx.jpg",
"release_date": 1212537600
},
"sort": [
1
]
}
]
}
}
- took – 执行搜索的时间(以毫秒为单位)
- timed_out – 搜索是否超时
- _shards – 搜索了多少个分片,以及搜索成功/失败的分片数
- hits – 搜索结果
- hits.total – 符合搜索条件的文档总数
- hits.hits – 搜索结果数组(默认为前10个文档)
- hits.sort – 结果的排序键
- hits._score – 文档的相关性,数字越高,文档越相关。
更多参数解释可以查看官方文档
DSL查询
Elasticsearch 提供了基于 JSON 的完整 Query DSL(Domain Specific Language)来定义查询。
- term查询
查询ID为1的文档:
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"term": {
"id": 1
}
}
}
一般使用term检索非文本的精确值,例如商品价格、商品ID、登录账号等。
- terms查询
相当于多个term检索, 类似于SQL中in关键字的用法, 即在某些给定的数据中检索:
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"terms": {
"title.keyword": [
"Kung Fu Panda", "Batman"
]
}
}
}
一般使用term检索非文本的精确值,例如商品价格、商品ID、登录账号等。
- match文本模糊查询
查询标题包含panda的文档:
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"match": {
"title": "panda"
}
}
}
- keyword匹配精确值
使用keyword后,文本精确值必须是匹配值才算匹配成功
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"match": {
"title.keyword": "Kung Fu Panda"
}
}
}
- match_phrase短语匹配
使用match时会自动分词,如果不想分词,想查询一个完整的短语就可以使用短语匹配
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"match_phrase": {
"title": "Kung Fu"
}
}
}
- multi_match多字段匹配
在title和overview两个字段中匹配关键词
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"multi_match": {
"query": "Kung Fu",
"fields": ["title","overview"]
}
}
}
注: 查询内容会分词
- filer过滤查询
filer与must,must_not,should的不同: 是否满足都不会增加评分
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "panda"
}
}
],
"filter": {
"range": {
"release_date": {
"gte": 1212537500,
"lte": 1212537700
}
}
}
}
}
}
- 复合查询:
例如查询标题中包含panda并且发布时间在指定范围的文档
GET http://127.0.0.1:9200/movies/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"release_date": {
"gte": 1212537500,
"lte": 1212537700
}
}
},
{
"match": {
"title": "panda"
}
}
],
"boost": 1.0
}
}
}
bool复合查询可以理解为与, 多个查询条件都要一起满足。
must,must_not,should
- must: 必须满足
- must_not : 必须不满足
- should: 满不满足都可以,满足评分会更高
跟多用法参考官方文档
参考:
https://blog.csdn.net/Tc_lccc/article/details/118061349
https://blog.csdn.net/weixin_30650039/article/details/98046946
